




Client
Il s'agit d'un projet de démonstration non commercial, spécialement conçu pour montrer notre expertise en machine learning et la résolution de problèmes complexes en développement logiciel.
Défi
Les commerçants rencontrent souvent des difficultés pour optimiser leurs stocks. Trop de stock peut limiter l'espace pour d'autres marchandises, tandis qu'un stock insuffisant peut faire fuir les clients vers la concurrence.
Nous avons remarqué que le marché se tournait de plus en plus vers l'analyse prédictive pour résoudre ce problème. Cependant, cela nécessite des données de vente spécifiques à chaque produit, ce qui est difficile à obtenir à partir d'outils open source.
“Anticiper la demande dans le commerce de détail nécessite des données de vente spécifiques à chaque produit, une rareté dans les outils open source.”
Elinext n'avait pas encore d'expérience dans l'analyse prédictive dans le secteur du commerce de détail. Nous avons donc modélisé un cas pour apprendre les spécificités du secteur.
Processus
Notre équipe était composée de deux ingénieurs en machine learning. Nous avions de l'expérience en intelligence artificielle et en projets où les données essentielles n'étaient pas facilement disponibles, mais nous n'avions jamais construit de modèles de machine learning spécifiquement pour le commerce de détail.
Les deux principaux défis étaient le manque de données et l'absence d'expérience spécifique. Voici comment nous avons relevé ces défis.
Collecte des données
Nous avons commencé à résoudre le problème des données par la recherche. Les détaillants ne partagent pas facilement leurs informations précieuses, et les études que nous avons trouvées ne fournissaient pas d'informations spécifiques. Cependant, nous avons rapidement réalisé qu'il y avait un endroit où trouver des chiffres utiles: les rapports de compétitions de programmation.
Notre recherche nous a menés au M5 Forecasting Accuracy 2020, l'une des compétitions Makridakis. Connue des développeurs depuis 1982, ce défi est organisé par l'Université de Nicosie et Kaggle, une communauté en ligne de data scientists et de praticiens du machine learning.
“Nous avons trouvé des données de vente utiles provenant de Walmart grâce à la compétition M5 Forecasting Accuracy.”
La compétition M5 Accuracy originale a rassemblé 5 500 participants qui ont étudié les données de plus de 30 000 produits fournis par Walmart. Le fait qu'un grand détaillant fournisse de telles données complètes pour des expériences avec l'IA en faisait une source de connaissance unique.
C'est ce qui en a fait l'étude de cas parfaite pour nous.
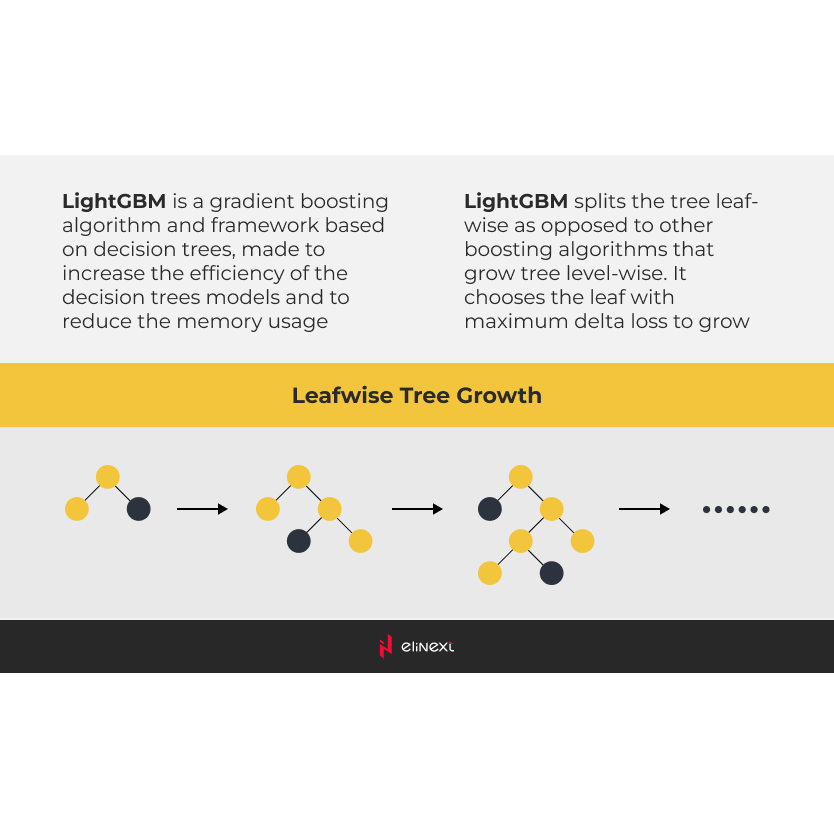
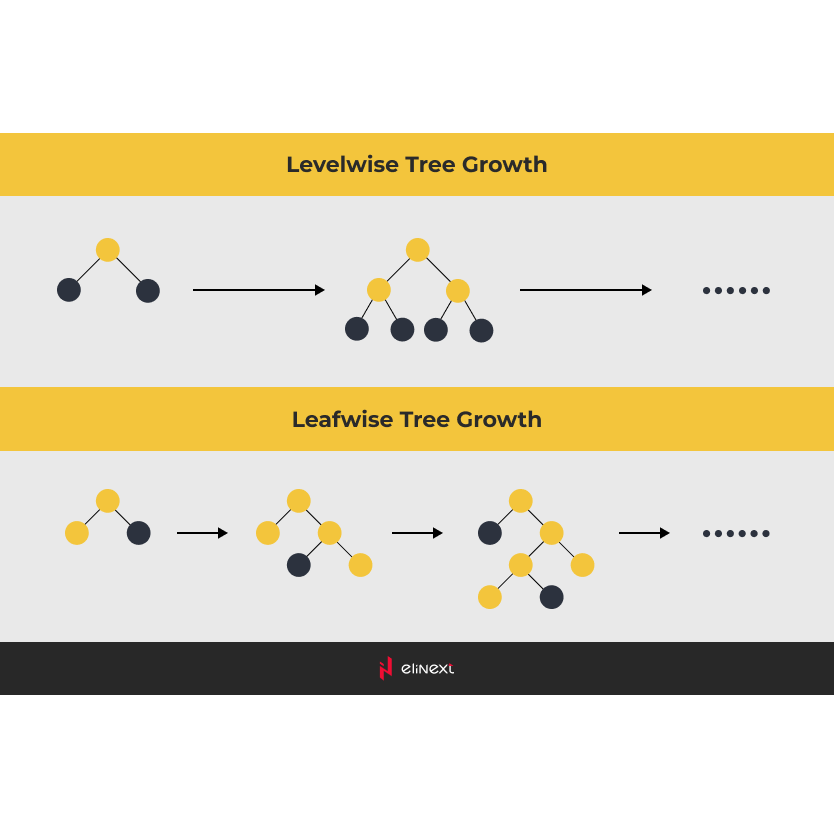
Sélection du Framework de Développement
Elinext n'avait pas d'expérience préalable dans la création d'analyses prédictives pour le commerce de détail. Nous avons donc commencé par analyser les approches qui se sont avérées les plus réussies lors de la compétition. C'était un moyen sûr d'éviter de répéter les erreurs de nos prédécesseurs et de réduire le temps de développement, par rapport à un travail depuis zéro.
Nous avons trouvé des critiques de certaines de ces approches, ce qui était un bon point de départ. Malheureusement, ces critiques manquaient de nombreux détails essentiels. Seules quelques descriptions étaient accompagnées de code, et celles-ci n'incluaient pas les meilleurs participants de la compétition.
“Nous avons commencé par analyser les approches qui se sont avérées les plus réussies.”
Néanmoins, nous avons approfondi les approches gagnantes et fait une découverte importante : les arbres de décision surpassaient les réseaux neuronaux. Plus précisément, les gagnants faisaient référence aux machines à gradient boosting (GBM). Parmi celles-ci, LightGBM s'est révélé être le meilleur framework pour construire un modèle de machine learning adapté à cette tâche.
Produit
Définition du Jeu de Données d'Entraînement
Les données que nous avons trouvées dans le cadre de la compétition, bien que précieuses, représentaient un défi en elles-mêmes.
Tout d'abord, environ 60 % des enregistrements étaient à zéro. Cela rendait les données difficiles à utiliser avec des méthodes analytiques standards pour capturer les dépendances. Ce type de données avait été choisi pour pousser les concurrents à aller au-delà des applications pratiques et contribuer au développement de méthodes théoriques.
Les ensembles de données avec autant de lacunes affectent potentiellement la précision des prévisions. Nous ne savions pas si ces enregistrements à zéro étaient dus à une faible demande ou à des interruptions d'approvisionnement. Et il restait à deviner comment ces zéros étaient liés aux observations de la demande des autres jours.
Cependant, les approches qui ont réussi dans la compétition peuvent donner des résultats étonnants lorsqu'elles sont appliquées à des ensembles de données plus complets et plus complets.
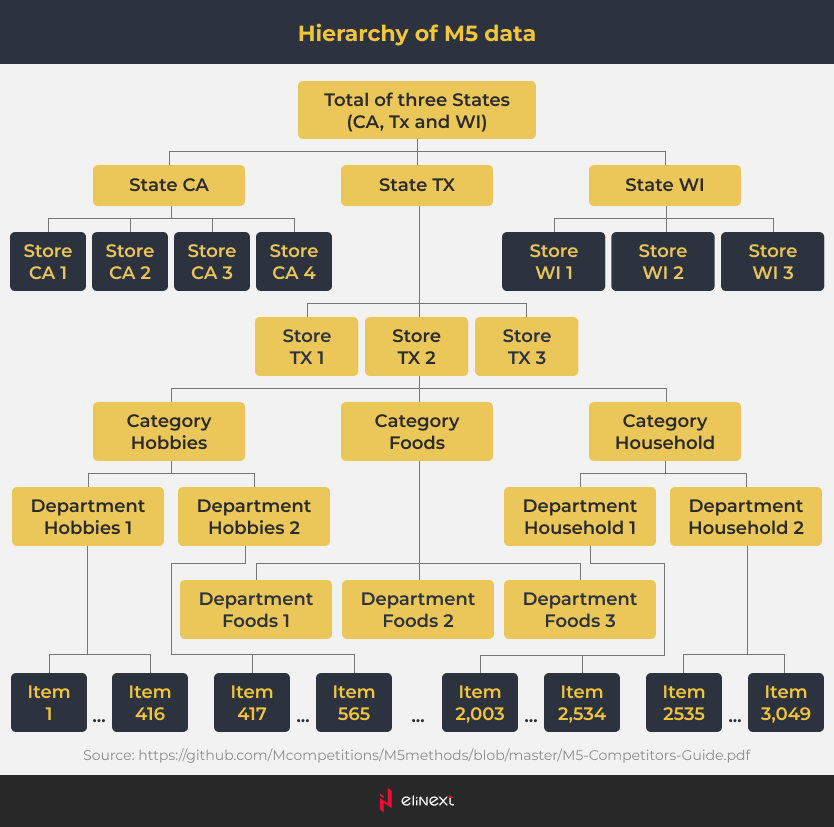
Nous avons trouvé des données de vente pour chacun des 3 049 produits provenant de 10 magasins dans 3 États (Californie, Texas et Wisconsin) sur une période de 28 jours. Les données étaient également regroupées par catégorie (alimentation, ménager et loisirs) et par département (par exemple, Food 1, Food 2). En outre, les facteurs incluaient l'activité publicitaire et promotionnelle, des événements comme les jours fériés, les jours de la semaine, et plus encore.
En conséquence, l'ensemble de données comportait 42 840 séries chronologiques. Cela se rapproche des situations réelles où les détaillants gèrent des milliers de produits. En modélisant un grand nombre de séries chronologiques simultanément et dans des délais raisonnables, les concurrents ont créé une approche pratique et utile.
“L'ensemble de données comportait 42 840 séries chronologiques pour 3 049 produits provenant de 10 magasins dans 3 États sur une période de 28 jours.”
Construction du Modèle de Machine Learning
Nous avons suivi l'approche basée sur LightGBM, en utilisant notre propre configuration de modèle et des ensembles de fonctionnalités. Ces fonctionnalités incluaient près de 30 facteurs, tels que les valeurs de vente différées, les effets saisonniers, les prix, et plus encore. Beaucoup d'entre eux ont été utilisés par les participants à la compétition, comme le suggérait la nature même du projet.
Nous avons découvert que les valeurs de vente différées et les identifiants de produit avaient le plus d'influence sur les résultats de notre modèle. Chaque identifiant de produit se réfère à une série particulière, ce qui a permis au modèle de calculer les dynamiques de vente spécifiques à chaque produit.
Cherchant à créer un modèle applicable à la vie réelle, nous avons essayé de calculer quelle précision on pouvait réellement atteindre avec l'ensemble de données disponible. Voici ce que nous avons fait.
Nous avons sélectionné environ 20 séries chronologiques presque sans zéros. Ces produits appartenaient à la catégorie alimentaire. Nous avons donc évité la complexité principale de l'ensemble de données (les zéros), et nous pouvons raisonnablement supposer que les séries suivent des schémas plus prévisibles que les autres catégories de produits. Les cycles de vente des aliments sont plus courts, leurs réactions aux effets calendaires sont plus évidentes, etc. Nous pensons donc que la puissance de prévision de toute approche de modélisation sur cet ensemble de données devrait être plus élevée que sur l'ensemble complet. Ce jeu de données est notre référence dorée pour l'ensemble de données complet.
Nous avons modélisé ce sous-ensemble de données avec une approche statistique très conventionnelle, ARIMA. LightGBM est beaucoup plus efficace, du moins en termes de temps de traitement, pour les grands ensembles de données. Mais, pour un petit ensemble de données, ARIMA suffisait pour rapidement révéler la vérité. Pour la plupart des séries, nous avons créé des modèles qui respectaient toutes les conventions de l'analyse des séries chronologiques, y compris les termes d'erreur de bruit blanc. Ainsi, l'ensemble du schéma dépend des dynamiques des variables, dans notre cas les ventes quotidiennes, qui sont ensuite couvertes par le modèle. Le bruit blanc est un processus purement imprévisible que nous ne pouvons pas modéliser. Nous en concluons qu'une série couverte par un modèle ne peut pas être mieux modélisée par une autre alternative. Nous pouvons utiliser ces séries comme référence dorée pour notre ensemble de données. Pour ces séries, la meilleure précision de prévision en termes absolus que nous avons atteinte n'a pas dépassé de manière substantielle 70 %. Pour l'ensemble de données complet (ici nous pouvons seulement supposer), elle ne peut probablement pas atteindre un taux plus élevé avec une autre approche.
Nous ne pouvons pas nous attendre à une précision absolue impressionnante avec les données de la compétition M5, bien que la situation puisse être différente avec d'autres ensembles de données de commerce de détail. Le processus de modélisation dépend des données. Il doit révéler les processus de génération de données commerciales derrière un ensemble de données réel.
Mais pour cet ensemble de données particulier, nous pouvons mesurer nos compétences en modélisation en termes relatifs, en les comparant avec les résultats des leaders.
Résultats
Les organisateurs de la compétition ont classé les concurrents en fonction du taux d'erreur quadratique moyenne pondérée (WRMSSE). Plus le taux était bas, meilleur était le résultat du développeur. Nous avons obtenu un score de 0,54, ce qui nous a placés dans le top 10 parmi 5 500 participants.
Cependant, l'algorithme que nous avons développé peut être utilisé au-delà de la simple prévision de la demande. Il permet de découvrir des interdépendances entre plusieurs facteurs, invisibles à un œil non averti. Les détaillants peuvent utiliser ces interdépendances pour mieux planifier leurs budgets et s'assurer que les produits arrivent dans les paniers des clients plus rapidement.
“Elinext a atteint une précision de prédiction parmi le top 10 sur 5 500 concurrents.”