



Défi
La société avait récemment lancé une boutique en ligne. L'équipe du site Web a passé beaucoup de temps à répondre aux questions des acheteurs et à modérer les critiques et les commentaires. Sans surprise, certaines personnes ont ignoré les règles du site Web et l'éthique généralement acceptée, en utilisant des expressions haineuses et des insultes dans leurs messages.
La meilleure façon de résoudre un problème comme celui-là? L’automatisation. La société souhaitait utiliser l'intelligence artificielle (IA) pour créer un détecteur de discours haineux et un bot de FAQ. Elle a donc cherché un préstataire capable de le faire et est tombé sur Elinext. Nous avons été choisis pour ce travail parce que nous avions les compétences et les ressources requises.
Solution
Elinext a construit une petite équipe Agile et s'est mis au travail immédiatement. Tout d'abord, nous avons examiné la technologie de traitement du langage naturel (NLP) la plus avancée disponible. Nos résultats suggèrent que nous devrions traiter la conception et le développement d’un chatbot et d’un détecteur de discours haineux comme deux projets parallèles d'apprentissage automatique (ML).
Détecteur de Discours Haineux
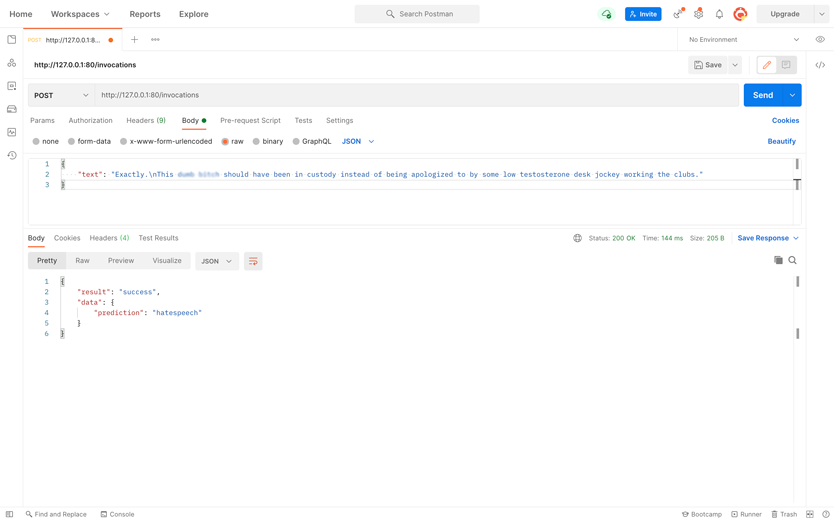
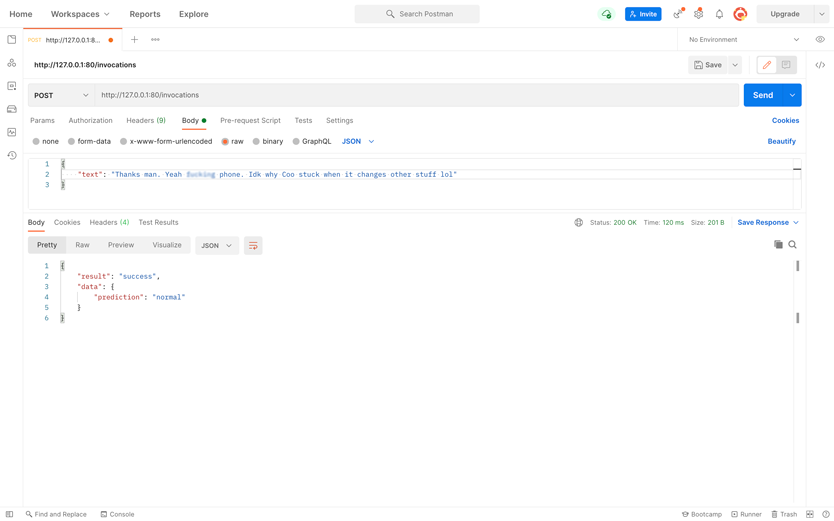
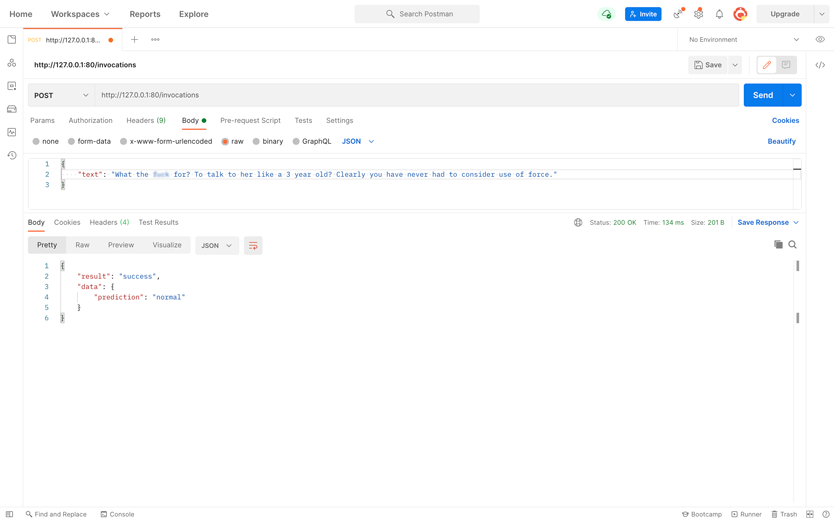
Nous avions besoin de construire un modèle ML qui identifierait le texte inapproprié généré par l'utilisateur. Le modèle nécessitait un ensemble de données, une sélection de mots d'arrêt et de phrases pour l'apprentissage. Et c'est quelque chose que notre client en tant que nouvelle entreprise n'avait pas.
La meilleure solution était de trouver un ensemble de données publiques sur le langage haineux. Après avoir examiné plusieurs options, nous avons choisi HateXplain.
Nous avons créé un référentiel GitHub et y avons placé l'ensemble de données aux côtés d'une IA open source: Generative Pre-trained Transformer 2 (GPT-2). Ensuite, nous avons automatisé la formation à l'IA sur l'ensemble de données à l'aide d'Amazon Elastic Compute Cloud (Amazon EC2) fonctionnant sur un GPU Nvidia.
Le code du service Web perspective est devenu l'élément final du référentiel. Une fois qu'il a été téléchargé, l'application a automatiquement déployé le service en tant que conteneur Docker à côté des fichiers binaires du modèle. Ce dernier permettra au client d'analyser et de déboguer l'application à l'avenir.
Le processus est démarré en exécutant le serveur HTTP héberge le modèle GPT2 et le modèle tokenizer. Une fois que le serveur reçoit un fragment de texte envoyé par un utilisateur, le tokenizer divise le texte en unités sémantiques à digérer par GPT-2.
Ensuite, les unités sémantiques sont exécutées via la fonction softmax. La fonction les classe et le système marque le texte d'entrée comme normal, haineux ou offensant pour l'administrateur du site Web.
Nous avons automatisé le processus de A à Z en utilisant des serveurs virtuels dans GitHub Actions, en économisant à la fois notre matériel et celui des clients.
Fait intéressant, l'IA peut discerner les messages haineux et ceux qui utilisent simplement des expressions fortes. Il peut également distinguer la rhétorique agressive des mots d'argot. La précision globale du modèle est d'environ 68%, ce qui signifie qu'il peut réduire le temps de modération.
Bot d'Aide FAQ
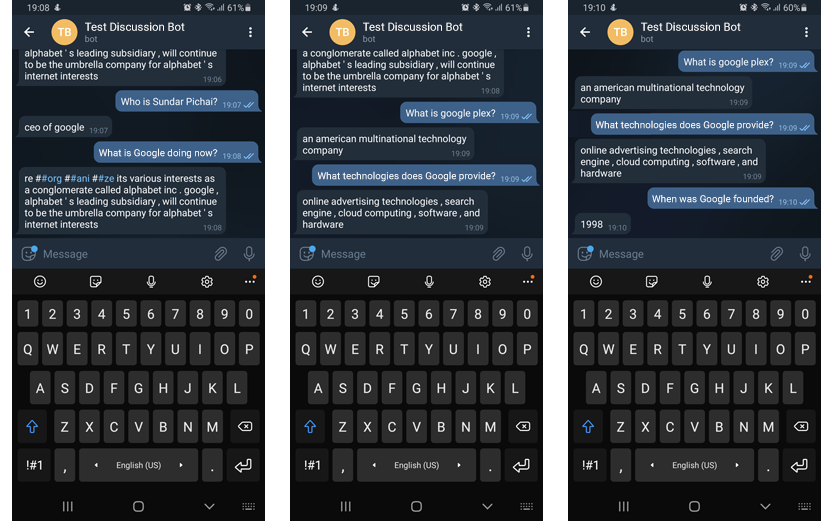
Le bot FAQ était nécessaire pour répondre aux questions des utilisateurs liées au commerce électronique. Cela signifie que nous avons dû créer une base de connaissances, permettant au bot de comprendre les requêtes des utilisateurs et de rechercher des informations dans la base.
Nous avons forcé le bot à comprendre les requêtes bot à l'aide d'un modèle de reconnaissance de la langue anglaise pré-entraîné: Bidirectional Encoder Representations from Transformers (BERT).
Mais avant d'être reconnu, le texte doit entrer dans le système. Comment cela se passe-t-il?
Nous avons configuré l'API HTTP et l'API Telegram, activant deux options. Tout d'abord, le visiteur du site Web ouvre une fenêtre de discussion pour discuter avec le bot. Le bot leur suggérera également de passer à Telegram et de leur envoyer un lien vers le chat.
Le serveur Web traitera la requête et recherchera les informations dans le contexte préparé par un administrateur de site Web. Les administrateurs peuvent modifier, enrichir et remplacer le contexte.
Bien sûr, les gens font parfois des fautes de frappe ou d'orthographe. Mais notre bot interprétera toujours correctement la requête (à moins qu'il ne s'agisse d'un désordre de lettres indigeste) et fournira une réponse. Ainsi, le processus ressemble à une conversation avec un opérateur qualifié.
Résultat
En deux semaines, nous avons créé une application qui a permis au client d'économiser des centaines d'heures de travail d'administrateur de site Web.
De plus, les acheteurs ne sont pas laissés à parcourir une longue FAQ divisée en plusieurs sections. Au lieu de cela, ils peuvent demander au chatbot ce qui les intéresse et recevoir une réponse immédiatement.
Les deux applications que nous avons créées ont permis au client d'économiser du temps et de l'argent et de simplifier le processus d'achat.